Abstract
A recent trend among generalizable novel view synthesis methods is to learn a rendering operator acting over single camera rays.


Sparse DTU
3 views
Sparse RFF
3 views
Generalizable DTU
unknown scene
Generalizable RFF
known scene
ILSH
ICCV 23 challenge
A recent trend among generalizable novel view synthesis methods is to learn a rendering operator acting over single camera rays.
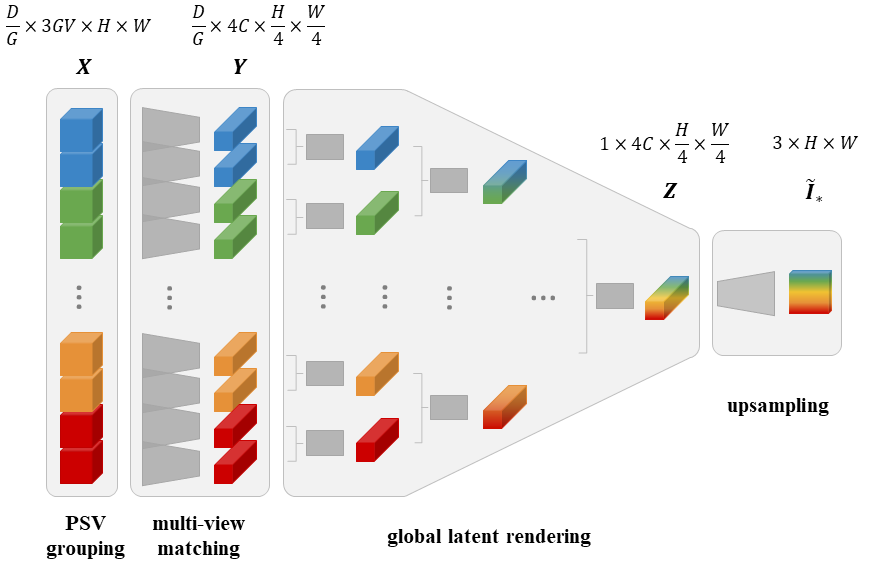
Overview of ConvGLR. The 4D grouped PSV $\boldsymbol{X}$ is turned into a latent volumetric representation $\boldsymbol{Y}$, then rendered into a latent novel view $\boldsymbol{Z}$ and finally upsampled into the novel view $\boldsymbol{\tilde{I}}_{\!\ast}$. The dark gray blocks are implemented with 2D convolutions and resblocks.